Identifying the existence of intersections in intervals is a classic task where, given a table with a set of intervals, you need to check whether any intersections exist. This is often done to verify the validity of data that holds intervals that are not supposed to have any intersections between them. For example, when you keep history of changes to rows by maintaining multiple versions of a row, the same row is not supposed to have intersecting versions. This article first describes a classic solution for the task and explains why it’s extremely inefficient, and then provides a highly efficient solution.
In my examples, I’ll use a table called Intervals with the columns keycol, low and high. Both solutions that I’ll provide will benefit from an index on (low, high, keycol). The low and high columns are integer columns representing the delimiters of the intervals. In practice, you will probably mostly work with date and time delimiters and not integers, but the solutions I’ll provide will work as written either way. The intervals in my table are closed-open ones, meaning that the delimiter low is inclusive and the delimiter high is exclusive.
The task in question is to write a query that returns 1 if any intersections exist in the data and 0 otherwise. Intersections exist if there’s at least one case of two intervals Iw and Iz where Iw.low < Iz.high and Iw.high > Iz.low. For instance, the intervals (10, 20) and (19, 21) intersect, and so do (10, 20), (15, 15). The last interval is referred to as a degenerate interval (low = high). However, the intervals (10, 20) and (20, 30) don’t intersect.
Sample Data
To help populate the table Intervals with sample data I’ll use a helper function called GetNums, which generates a sequence of integers within a given range. Use the following code to create the function:
SET NOCOUNT ON;
USE tempdb;
IF OBJECT_ID(N'dbo.GetNums', N'IF') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
Run the following code to create the table Intervals, including the supporting index:
IF OBJECT_ID(N'dbo.Intervals', N'U') IS NOT NULL DROP TABLE dbo.Intervals;
GO
CREATE TABLE dbo.Intervals
(
keycol INT NOT NULL
CONSTRAINT PK_Intervals PRIMARY KEY,
low INT NOT NULL,
high INT NOT NULL,
CONSTRAINT CHK_Intervals_high_gteq_low CHECK(high >= low),
INDEX idx_low_high_keycol NONCLUSTERED(low, high, keycol)
);
Use the following code to populate the table with a desired number of nonintersecting intervals:
DECLARE @numintervals AS INT = 10000; -- change as needed
TRUNCATE TABLE dbo.Intervals ;
INSERT INTO dbo.Intervals WITH (TABLOCK) (keycol, low, high)
SELECT n, (n - 1) * 10 + 1 AS low, n * 10 AS high
FROM dbo.GetNums(1, @numintervals) AS Nums;
This code populates the table initially with 10,000 nonintersecting intervals, but you can feel free to test the solutions with different table sizes. Use the following code to query a sample of 10 rows from the table:
SELECT TOP (10) keycol, low, high
FROM dbo.Intervals
ORDER BY low, high, keycol;
This code generates the following output:
keycol low high
----------- ----------- -----------
1 1 10
2 11 20
3 21 30
4 31 40
5 41 50
6 51 60
7 61 70
8 71 80
9 81 90
10 91 100
Note that I use sample data with nonintersecting intervals to test the performance of the solutions in the worst-case scenario. To check the validity of the solution, that it detects a case where intersections exist, use the following code to add an intersecting interval:
INSERT INTO dbo.Intervals(keycol, low, high)
SELECT TOP (1) 2147483647 AS keycol, low, high
FROM dbo.Intervals
ORDER BY low DESC, high DESC, keycol DESC;
Later you can use the following code when you want to remove the intersecting interval:
DELETE FROM dbo.Intervals WHERE keycol = 2147483647;
Traditional Solution (Solution 1)
The traditional solution (call it Solution 1) uses two EXISTS predicates. An inner EXISTS predicate with a subquery identifies intervals that intersect with other intervals. An outer EXISTS predicate checks whether the inner query returns at least one interval that intersects with other intervals. The code aliases the outer instance of the Intervals table I1 and the inner instance I2. The subquery filters intervals in I2 that intersect with the interval in I1--i.e., where I1.keycol < I2.keycol (to make sure we’re not comparing an interval with itself), and I1.low < I2.high AND I1.high > I2.low. Here’s the complete solution code:
SELECT
CASE
WHEN EXISTS
( SELECT *
FROM dbo.Intervals AS I1
WHERE EXISTS
( SELECT *
FROM dbo.Intervals AS I2
WHERE I1.keycol < I2.keycol
AND I1.low < I2.high
AND I1.high > I2.low ) )
THEN 1
ELSE 0
END AS intersectionsexist;
The plan for this query is shown in Figure 1 for the sample data size of 10,000 rows.
Figure 1: Plan for Solution 1

The Constant Scan operator defines a table of constants with a single row. The outer Nested Loops (Left Semi Join) operator short-circuits the inner work as soon as a row is found, which would mean that at least one interval that intersects with other intervals exists.
The inner Nested Loops (Left Semi Join) operator short-circuits the work that looks for intersecting intervals for a given interval as soon as one intersecting case is found.
When no intersections exist, no short-circuiting takes place. There’s one full pass over the data for the outer input of the inner Nested Loops operator, plus a whole pass over the data per row. This means that for a sample size of N rows, the number of rows scanned by this plan is N + N2. For example, with only 10,000 rows in the table, this plan ends up scanning 100,010,000 rows. This is pretty bad in terms of the scaling of this solution.
Based on assumptions called inclusion and containment, the optimizer makes a choice to use a scan and not a seek in the index since it assumes that if you’re looking for something, it exists. When no intersections exist, this results in a full scan of the index per row. Furthermore, here there’s no early filtering of rows done by the storage engine.
It took this query 14 seconds to complete on my system with only 10,000 rows in the table.
You could improve performance by forcing SQL Server to perform a seek in the index based on the range predicate that involves the leading index key (I2.low < I1.high) using the FORCESEEK operator. This will have two advantages. One advantage is that even though you will pay the cost of a seek to get to the leaf per row, in average, you will scan about half the rows per row (1 for the first, 2 for the second, N for the Nth)--therefore, (N + N2) / 2, plus the extra pass for the outer input of the join, totaling N + (N + N2) / 2. Another advantage is that such a plan should be able to push the filtering of the residual predicates (the ones beside the seek predicate) to the storage engine. Such early filtering by the storage engine is more efficient than later filtering by the query processor.
Here’s Solution 1 with the FORCESEEK hint:
SELECT
CASE
WHEN EXISTS
( SELECT *
FROM dbo.Intervals AS I1
WHERE EXISTS
( SELECT *
FROM dbo.Intervals AS I2 WITH (FORCESEEK)
WHERE I1.keycol < I2.keycol
AND I1.low < I2.high
AND I1.high > I2.low ) )
THEN 1
ELSE 0
END AS intersectionsexist;
The plan for this solution is shown in Figure 2.
Figure 2: Plan for Solution 1 with FORCESEEK

You can see both the seek predicate that is based on the range predicate against the leading index key, and the early filtering that is done by the storage engine to handle the residual predicates, in the properties of the bottom Index Seek operator. As mentioned, in addition to the cost of the seeks that get to the leaf of the index per row, this plan processes about N + (N + N2) / 2 rows (50,015,000 with our sample data of 10,000 rows), compared to twice with the previous solution. This fact, plus the early filtering by the storage engine, results in query run time of 2 seconds against the table with the 10,000 rows, compared to 14 seconds without the FORCESEEK hint. Courtesy of Adam Machanic, as a troubleshooting tip, you can force the optimizer to replace the residual predicate with a query processor filter by adding the query trace flag 9130 (add OPTION (QUERYTRACEON 9130) at the end of the query). The last query will take several times longer to complete with this trace flag applied.
Unfortunately, though, even with FORCESEEK improvement, in terms of scaling, this solution still has quadratic complexity. I’ll provide the results of a performance test comparing the different solutions with different data sizes, but to give you a sense of how bad this improved solution scales, with a sample size of 10,000,000 rows, it would take it a bit over 20 days to complete on my machine!
New Solution (Solution 2)
Combining some logic, mathematics and window functions, you can do way better than the classic solution. The new solution is based on the assumption that If there's at least one case of intersecting intervals, there's at least one occurrence of two consecutive intervals Iw <= Iz (based on the order of low, high, keycol) that intersect.
Proof:
- Consider an example with only one case of intersecting intervals Iw and Iz, with the order Iw <= Iz.
Since they are intersecting intervals, Iw.low < Iz.high and Iw.high > Iz.low.
First let's prove that if there's only one case of intersecting intervals like in (1), they must be consecutive. - If Iw and Iz were nonconsecutive, there would be at least one more interval Ix where Iw <= Ix <= Iz.
- According to (1), Ix doesn't intersect with Iw and Iz, therefore Iw.high <= Ix.low <= Ix.high <= Iz.low, therefore Iw.high <= Iz.low.
The conclusion from (3) that Iw.high <= Iz.low contradicts one of the outcomes of (1) saying that Iw.high > Iz.low. Therefore, if there's only one case of intersecting intervals, they must be consecutive.
Similar logic proves that if you add an interval Iy between any two intersecting intervals Iw and Iz, it must intersect with Iw, Iz or both. Because, if it didn't, you would have:
Iw.high <= Iy.low <= Iy.high <= Iz.low, which would mean that Iw.high <= Iz.low
This would contradict the outcome of (1) that Iw.high > Iz.low.
Therefore, if there's at least one case of intersecting intervals, there's at least one case of consecutive intervals that intersect.
Q.E.D.
Based on this conclusion, you could use a pair of LEAD functions to return for each current interval the delimiters of the next interval (based on the order of low, high, keycol), and check if they intersect. An EXISTS predicate can short-circuit the work as soon as one intersecting case exists. Here’s the new solution (call it Solution 2) based on this logic:
SELECT
CASE
WHEN EXISTS
( SELECT *
FROM ( SELECT keycol, low AS curlow, high AS curhigh,
LEAD(low) OVER(ORDER BY low, high, keycol) AS nextlow,
LEAD(high) OVER(ORDER BY low, high, keycol) AS nexthigh
FROM dbo.Intervals ) AS D
WHERE curlow < nexthigh
AND curhigh > nextlow )
THEN 1
ELSE 0
END AS intersectionsexist;
With a bit more logic you can simplify this solution by avoiding checking one of the predicates, and therefore removing the need for one of the two LEAD calculations.
Based on the order of Iw <= Iz, if Iw.high > Iz.low, then it must be that Iw.low < Iz.high, and therefore Iw and Iz intersect.
Proof:
We know that Iw.low <= Iz.low <= Iz.high, therefore Iw.low <= Iz.high. The only case where Iw.low = Iz.high would be if both were degenerate intervals (low = high). If indeed Iw.high > Iz.low both cannot be degenerate intervals. Therefore, Iw.low < Iz.high.
Q.E.D.
Here’s the query implementing Solution 2 after this simplification:
SELECT
CASE
WHEN EXISTS
( SELECT *
FROM ( SELECT keycol, low AS curlow, high AS curhigh,
LEAD(low) OVER(ORDER BY low, high, keycol) AS nextlow
FROM dbo.Intervals ) AS D
WHERE curhigh > nextlow )
THEN 1
ELSE 0
END AS intersectionsexist;
The plan for this query is shown in Figure 3.
Figure 3: Plan for Solution 2, row mode

Observe that there’s only one full pass over the data (when no intersections exist), based on index order; therefore, no explicit sorting is needed to support the LEAD function calculation. If intersections exist, the Left Semi Join operator short-circuits the scan as soon as the first intersection is found. This solution ran for 23 milliseconds with 10,000 rows on my machine, and it scales linearly. It’s not too bad, but believe it or not, if you’re running on SQL Server 2016 or later, you can further improve it. By creating a dummy nonclustered empty filtered columnstore index, you enable batch processing with the new batch mode Window Aggregate operator. For details about this trick, see the series of articles entitled What You Need to Know about the Batch Mode Window Aggregate Operator in SQL Server 2016, starting with Part 1.
Use the following code to add the index in question:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs_dummy
ON dbo.Intervals(keycol) WHERE keycol = -1 AND keycol = -2;
Our new simplified solution now generates the plan shown in Figure 4.
Figure 4: Plan for Solution 2, batch mode

You can see again the single ordered scan of the index, but this time the batch mode Window Aggregate operator handles the LEAD window function calculation instead of the original six row mode operators in the previous plan. This solution finishes in 12 milliseconds with 10,000 rows on my machine and also scales linearly. That’s not a bad improvement to go down from 14 seconds to 12 milliseconds. And that’s for a very small table. Since the classic solution scales in a quadratic manner and the new one in a linear manner, the difference grows significantly as the table grows. The next section provides the results of a performance test.
Performance test
I used the following code to compare the performance of the two solutions, with different data sizes:
SET NOCOUNT ON;
USE tempdb;
DECLARE @numintervals AS INT = 10000;
TRUNCATE TABLE dbo.Intervals ;
INSERT INTO dbo.Intervals WITH (TABLOCK) (keycol, low, high)
SELECT n, (n - 1) * 10 + 1 AS low, n * 10 AS high
FROM dbo.GetNums(1, @numintervals) AS Nums;
GO
DECLARE @start AS DATETIME2 = SYSDATETIME();
DECLARE @intersectionsexist AS INT =
CASE
WHEN EXISTS
( SELECT *
FROM dbo.Intervals AS I1
WHERE EXISTS
( SELECT *
FROM dbo.Intervals AS I2 WITH (FORCESEEK)
WHERE I1.keycol < I2.keycol
AND I1.low < I2.high
AND I1.high > I2.low ) )
THEN 1
ELSE 0
END;
PRINT 'Solution 1 duration: ' + STR(DATEDIFF(ms, @start, SYSDATETIME()) / 1000., 10, 3) + ' seconds.';
GO
DECLARE @start AS DATETIME2 = SYSDATETIME();
DECLARE @intersectionsexist AS INT =
CASE
WHEN EXISTS
( SELECT *
FROM ( SELECT keycol, low AS curlow, high AS curhigh,
LEAD(low) OVER(ORDER BY low, high, keycol) AS nextlow
FROM dbo.Intervals ) AS D
WHERE curhigh > nextlow )
THEN 1
ELSE 0
END;
PRINT 'Solution 2 duration: ' + STR(DATEDIFF(ms, @start, SYSDATETIME()) / 1000., 10, 3) + ' seconds.';
To disable batch processing use DBCC TRACEON (9453), or run the new solution without the dummy columnstore index in place.
Since the classic solution scales in a quadratic manner, beyond a certain number of rows it would take too long to wait for it to complete. So, based on the solution’s algorithmic complexity, you can interpolate the run times with large numbers of rows.
For example, recall that the complexity of the improved classic solution is N + (N + N^2) / 2. So I ran it with a sample of 50,000 rows and got a run time of 44.514 seconds. I computed an average processing time per row by reverse engineering the complexity, using the following calculation:
DECLARE @numrows AS INT = 50000, @runtimems AS INT = 44.514;
SELECT @runtimems / (@numrows + (@numrows + SQUARE(@numrows)) / 2);
I got the result of 3.51978881267124E-08 seconds per row.
Then I could predict the run time of a query against a table of any given size by plugging the per-row run time in the formula with the solution’s complexity, like so:
DECLARE @perrow AS FLOAT =3.51978881267124E-08, @numrows AS INT = 1000000;
SELECT (@numrows + (@numrows + SQUARE(@numrows)) / 2) * @perrow;
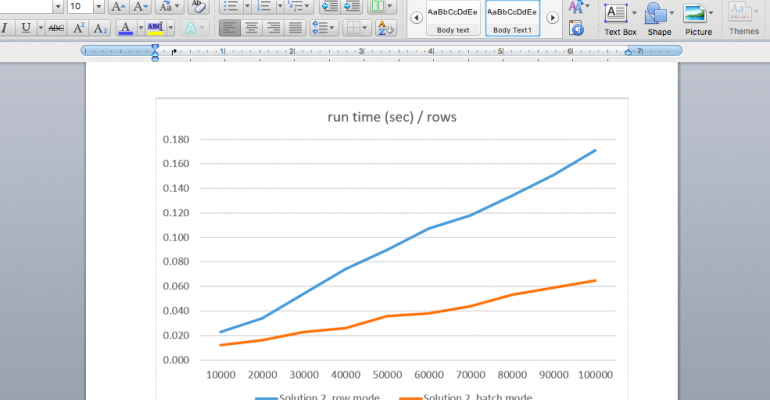
Figure 5 shows the results of the performance test comparing the new solution (Solution 2) under row mode and under batch mode. Figure 6 compares the improved classic solution (Solution 1) with the new solution (Solution 2) under batch mode.
Figure 5: Graph comparing Solution 2 row mode vs. batch mode

Figure 6: Graph comparing Solution 1 and Solution 2

As you can see, under batch mode Solution 2 takes about a third of the time compared to under row mode on my test system.
With 10,000,000 rows, improved Solution 1 would take a bit over 20 days to complete on my machine, compared to Solution 2 under batch mode, which takes 6 seconds!
Conclusion
Twenty days or 6 seconds--which one should we go for ... ?
I keep being surprised by how much you can sometimes improve query performance by applying query revisions. This exercise also shows how much an understanding of algorithmic complexity and a bit of logic and math can help you in optimizing your T-SQL querying solutions.
And, before I conclude, let me share the virtual whiteboard that I used when working on the logic that supports the new solution …