As we start off in 2014, I thought it would be a good idea to look back at technology that gained increasing visibility during 2013. In terms of Exchange, there’s really only one candidate in that space: Managed Availability, otherwise known as the “Rodney Dangerfield” of the product (the reader is invited to figure out that analogy for their own amusement). I’ll cover the topic in two posts: this will cover the logic and rationale behind why Managed Availability exists. The next will look at the implementation and experience in Exchange 2013.
Here’s the thing: when you review the costs of computer operations, human beings bubble up as the most expensive piece of the equation. Humans want to be paid salaries and benefits and need a lot of tender loving care (or at least some) from management before they function at optimum levels. And they get sick or want to take holidays so they have to be organized into schedules so that sufficient people are available to get work done.
In fact, the only reason why people are used in general-purpose IT operations is a little thing called “knowledge”. Computers and other machines aren’t yet at the stage where they can function in an unsupervised mode. Computers are great at processing well-defined sets of work but people have to provide that work and check that the work completes successfully.
All in all, in terms of IT operations, people are an essential, expensive, and time-demanding resource. It has been so for many years and I suspect that the same situation will continue.
In the world of datacenter operations the problem is even more pressing. Where a small company can afford to have one or two administrators looking after twenty or thirty servers, a company that wishes to offer economic cloud services cannot afford to deploy the same ratio of people to computers as the number of servers swells into the thousands or tens of thousands. In fact, you cannot afford to have people touch servers at all, at least not on an ongoing basis. Automation is critical and the focus for human tasks moves from mundane daily server management to figuring out how to automate themselves out of a job.
The Windows group have long realized that the days of personal server management are gone. Anyone who has listened to Chief Windows Architect Jeffrey Snover will come away convinced that he has been on a journey to automation for years. Many times Jeffrey has said that he is dedicated to prising the fingers of administrators off keyboards connected directly to servers. In his view, computer management is something that you automate and if a task cannot be automated, it should be performed remotely.
PowerShell is the biggest and best representation of that journey. Once mocked as a weak “me too” UNIX-like shell, PowerShell is now acknowledged as the cornerstone of efficient Windows server management. Without PowerShell, Microsoft could not manage their Office 365 and Azure datacenters. Anyone who has not gotten the PowerShell message is living in a time warp, and not one in the future.
The advent of native data protection through the Database Availability Group (DAG) was acknowledged as the most impressive technical advance in Exchange 2010. Despite the fact that Exchange includes many PowerShell cmdlets to manage DAGs, Exchange 2010 DAG operations are pretty manual. It’s a good opportunity to build your own scripts to monitor the ebb and flow of replication within DAGs and to report on their configuration, a challenge that many MVPs and other experts gleefully accepted.
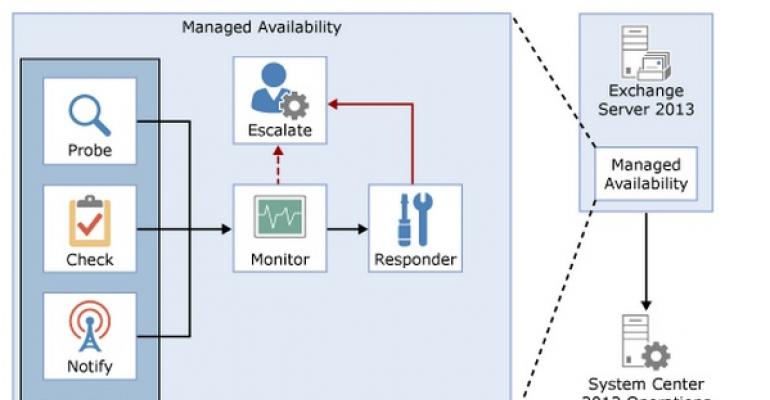
Managed Availability (MA) is the equivalent technical achievement in Exchange 2013. Like many technical advances, it takes time to appreciate and acknowledge the influence that something like Managed Availability has on an application. It’s not enough to simply set up and run a few Exchange 2013 servers in a test environment. You have to run the software in the fire of production to experience the true depth of the influence that Managed Availability exerts over DAGs, IIS, and other critical Exchange 2013 components.
Managed Availability is a great example of how Microsoft solves a problem that arises through its own datacenter operations that later results in useful technology being passed to on-premises customers. As Office 365 expanded to handle tens of millions of mailboxes, the number of servers and disks exploded. It’s relatively easy to plan, purchase, and commission the necessary hardware into datacenters along with the other activities such as datacenter build-out, provision of power and cooling, and security. Relatively in this sense means “bloody hard and bloody expensive but doable”. Amazon and Google do the much same thing in terms of build-out and commissioning for its datacenters as Microsoft does for theirs. The difference is the software that runs in each datacenter.
Turning to software, Google had an advantage in that it developed its applications from scratch. As Google’s applications evolved from initial release to beta to full-blown production, it built datacenter operations and monitoring alongside, learning as it went from operations so that it could continually improve the service delivered to users. The results have been excellent. For instance, Gmail has delivered a consistent and dependable service since it was launched.
By comparison, when it was faced by the need to expand its reach into cloud services, Microsoft took the on-premises version of Exchange and evolved it to serve two purposes. As VP of development Perry Clarke explained when we discussed the current state of Exchange, this was the only viable choice as it allowed Microsoft to bring its installed base along. But it is very hard to take software designed to run at a certain scale in an on-premises environment and transform it so that the same code can support tens of millions of clients representing thousands of companies connecting to multiple datacenters. And when you’ve figured that out, you still have to keep everything going to achieve an SLA of 99.9% and higher.
Managed Availability is a critical part of achieving that goal. It doesn’t exist in Exchange 2007, but Business Productivity Online Services (BPOS) was a very different beast that never had to function at the same scale. BPOS failed a lot too. An awful lot, but not unsurprisingly because Microsoft was attempting to deliver cloud services with software that was never designed for the cloud.
Exchange 2010 doesn’t include Managed Availability either. Exchange 2010 provided the basis for the initial version of Office 365 and demonstrated that the extra time for development since Exchange 2007 had been well used to evolve Exchange so that it could cope with the demands of cloud services more elegantly. However, we now had a situation where different code bases were used for Exchange Online and Exchange on-premises. Multiple code bases means additional complexity; additional complexity means extra cost and potential for error; and code errors lead to cloud outages, which are very bad, especially if you’re an Exchange engineer who is on call. Outages always seem to happen at the most inconvenient times, like 3am in the morning.
Exchange 2013 reversed the process and a single code base is now in use. Microsoft still needed to remove the potential for outages (if only to keep engineers safely tucked up in bed) and that’s the role of Managed Availability. Well, keeping servers up and running without human intervention rather than preserving the sleep patterns of engineers.
So the need for Managed Availability is obvious. Without automated monitoring and management it’s hard to keep datacenter operations at an economic level. But is Managed Availability useful to the on-premises crew? That’s another day’s work…
Follow Tony @12Knocksinna

